在本地运行大语言模型(LLM)已成为开发者、研究人员和AI爱好者的新潮流。然而,面对琳琅满目的模型库(从 Llama 3、Qwen 到 DeepSeek),一个最棘手的问题始终困扰着大家:“我的电脑到底能跑哪个模型?”
盲目下载几十GB的模型文件,结果启动时遭遇 OOM (Out Of Memory) 报错,不仅浪费了时间和带宽,更打击了探索的热情。为了解决这一痛点,开源工具 LLMFit 应运而生。它被誉为“本地AI硬件适配体检仪”,能在1秒钟内根据你的硬件配置,精准推荐最适合运行的模型及其量化版本。
🚀 LLMFit 是什么?
LLMFit 是一款跨平台(支持 Windows、macOS、Linux)的命令行工具,采用 TUI (Text User Interface) 终端图形界面设计。它不仅仅是一个简单的硬件检测器,更是一个智能的模型匹配引擎。
它的核心逻辑非常直观:
- 实时扫描:自动读取你当前的 CPU、系统内存 (RAM)、GPU 型号及显存 (VRAM) 状态。
- 海量比对:内置包含 500+ 款热门大模型的数据库(涵盖 30+ 家供应商,如 Meta、阿里、智谱、DeepSeek 等)。
- 智能计算:结合你的硬件瓶颈,模拟计算每个模型在不同量化精度(如 Q4_K_M, Q8_0)下的内存占用和推理速度。
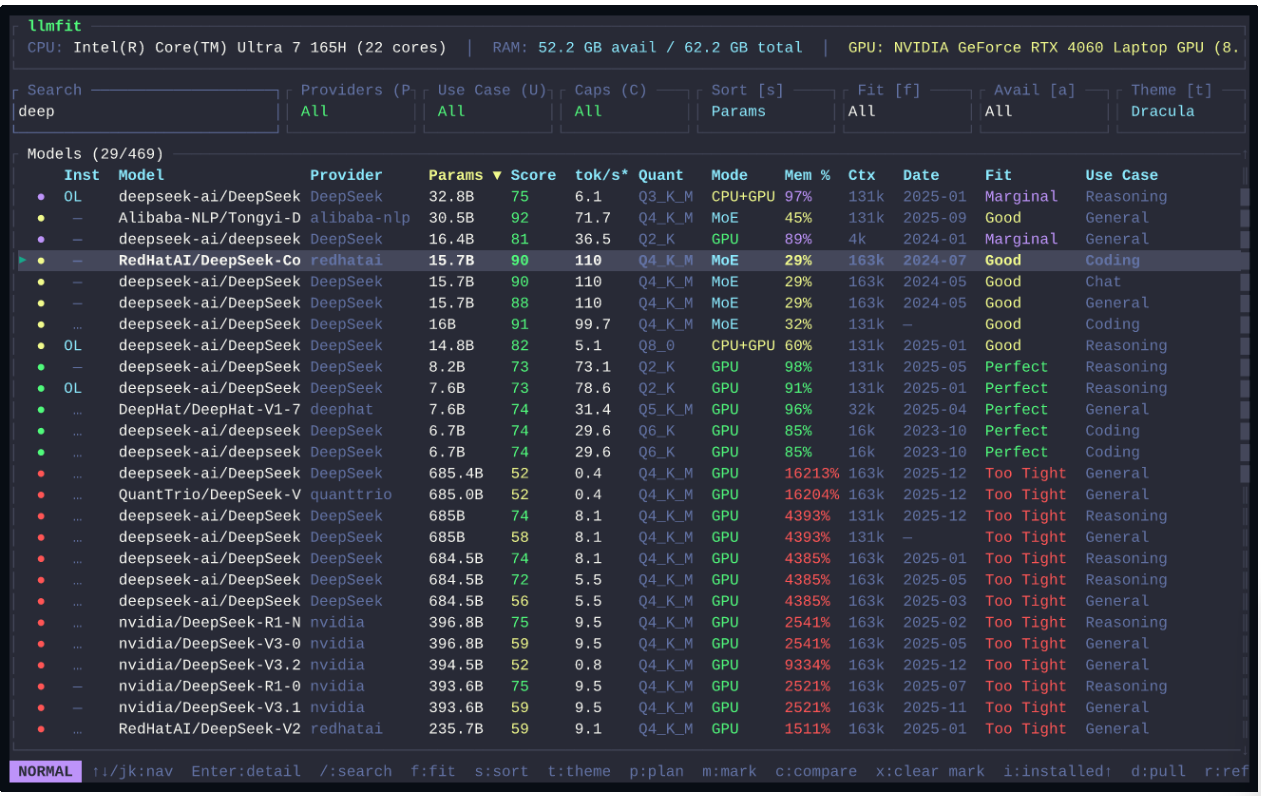
- 可视化推荐:在终端中以列表形式展示结果,直接告诉你哪些能跑、跑得有多快、该选哪个版本。
💡 核心功能亮点
1. 告别盲目试错,精准避雷
LLMFit 最大的价值在于预判。它能识别复杂的硬件架构,包括:
- NVIDIA GPU:精确计算 CUDA 核心与显存限制。
- Apple Silicon (M1/M2/M3):针对统一内存架构进行特殊优化,准确判断 macOS 下的运行能力。
- AMD GPU & CPU Only:即使没有独立显卡,也能计算出纯 CPU 推理的可行性。
对于 MoE (混合专家) 架构的模型(如 Mixtral、Grok),普通用户很难手动计算其实际显存需求,而 LLMFit 能准确估算其激活参数量对应的资源消耗,避免“看着显存够,一跑就崩”的尴尬。
2. 多维度评分体系
在 LLMFit 的界面中,每个模型都会获得四个维度的详细评估:
- 质量分 (Quality):基于参数量和模型家族的口碑评级。
- 速度预估 (Speed):预测在你的硬件上的生成速度 (Tokens/s),让你知道是“秒回”还是“龟速”。
- 适配度 (Fit):直观显示内存/显存占用率,绿色代表流畅,红色代表不可行。
- 上下文长度 (Context):显示在当前配置下支持的最大上下文窗口。
最终,工具会给出一个综合推荐分,并将无法运行的模型自动置灰或沉底,让用户一眼锁定目标。
3. 极简的交互体验
无需编写复杂的 Python 脚本,无需安装庞大的依赖库。LLMFit 通常以单二进制文件或简单的脚本形式存在。
- 启动即测:在终端输入一行命令(如
llmfit),界面瞬间加载。 - 实时筛选:支持键盘快速搜索模型名称(如输入 “qwen” 或 “30b”),列表实时过滤。
- 一键直达:部分版本甚至提供直接下载链接或 GGUF 文件跳转,打通“检测 – 下载 – 运行”的最后一步。
🛠️ 适用场景
- AI 初学者:不懂量化参数(Q4, Q5, Q8),只想找个能跑的模型聊天。
- 硬件发烧友:刚组装了新电脑(如 RTX 4090 + 64G RAM),想测试性能极限,看看能跑多大的模型。
- 开发者:需要为特定客户环境(如低配笔记本、边缘设备)选择合适的部署模型。
- MoE 模型玩家:专门针对 Mixtral、DBRX 等复杂架构进行资源评估。
📊 为什么选择本地部署?
LLMFit 的流行也折射出本地大模型部署的三大优势,而它正是这些优势的“守门人”:
- 隐私安全:数据完全留在本地,无需上传云端,适合处理敏感文档。
- 零成本运行:一旦硬件就位,推理无需按 Token 付费,无限次调用。
- 无网可用:在离线环境下依然能提供强大的 AI 辅助能力。
🔮 结语
项目地址:https://github.com/AlexsJones/llmfit/
在 AI 技术飞速迭代的今天,模型越来越大,硬件却相对固定。LLMFit 的出现,填补了“硬件能力”与“模型需求”之间的信息鸿沟。它将复杂的资源计算封装在简洁的终端界面之下,让每一位用户都能轻松找到属于自己的那个“完美模型”。
如果你也曾对着几百GB的模型文件犹豫不决,或者受够了反复的 OOM 报错,那么 LLMFit 绝对是你工具箱中不可或缺的利器。只需一秒,它就能告诉你:你的电脑,潜能无限。
注:LLMFit 为开源项目,具体安装方式和使用细节请参考其 GitHub 仓库或官方文档。模型数据库会随社区更新不断扩充,建议保持工具最新版本以获得最佳推荐效果。